Monday, November 25, 2019
Ola moves financial unit out of parent ANI Technologies
Documents show California's DMV is making ~$50M/year selling drivers' personal info, partaking in the highly criticized but common practice since at least 2013 (Joseph Cox/VICE)

Joseph Cox / VICE:
Documents show California's DMV is making ~$50M/year selling drivers' personal info, partaking in the highly criticized but common practice since at least 2013 — The California Department of Motor Vehicles is generating revenue of $50,000,000 a year through selling drivers' personal information …
Inside the Instagram AI that fills Explore with fresh, juicy content
Instagram has posted an article describing the behind-the-scenes machinery that fills the Explore tab in Instagram with new, interesting stuff every time you open it. It’s a bit technical, so here are five takeaways.
Even Instagram and Facebook have limited resources
Unlike the feed, which some still would prefer was simply chronological, the Explore tab needs to be algorithmically driven. But understanding what’s happening on an image-based social network and recommending new content to people is a problem that’s exactly as hard as you make it.
If these companies had infinite processing power and time, they’d probably come at the question of Explore a bit differently. But as it is they need to serve hundreds of millions of people on short notice and with merely enormous computing resources. I think they put this at the top of the post so people don’t wonder why they’re cutting corners.
It’s also easier to experiment and iterate when you can change stuff and see results quickly, they point out.
It’s all about the account, not the post
So much is posted to Instagram that it would be pretty much impossible to keep track of every photo individually, for recommendation purposes anyway. It’s simpler and more efficient to track accounts, since accounts tend to have themes or topics, from a broader one like “travel” to something highly specific, like especially round seals.
While liking one post from an account doesn’t necessarily mean you’ll like everything else from that account, it is a good indicator that you’re at least interested in the theme of that account. Even if it was this particular post of this particular cat that you wanted to heart because it reminds you of old Mittens, if you’re liking pictures from an account that mostly posts cats, that’s valuable information.
Complex habits inform the algorithm
Notably it isn’t just image features that Instagram uses to figure out what accounts are topically linked, though of course that kind of thing can be detected too. They also use your behavior.
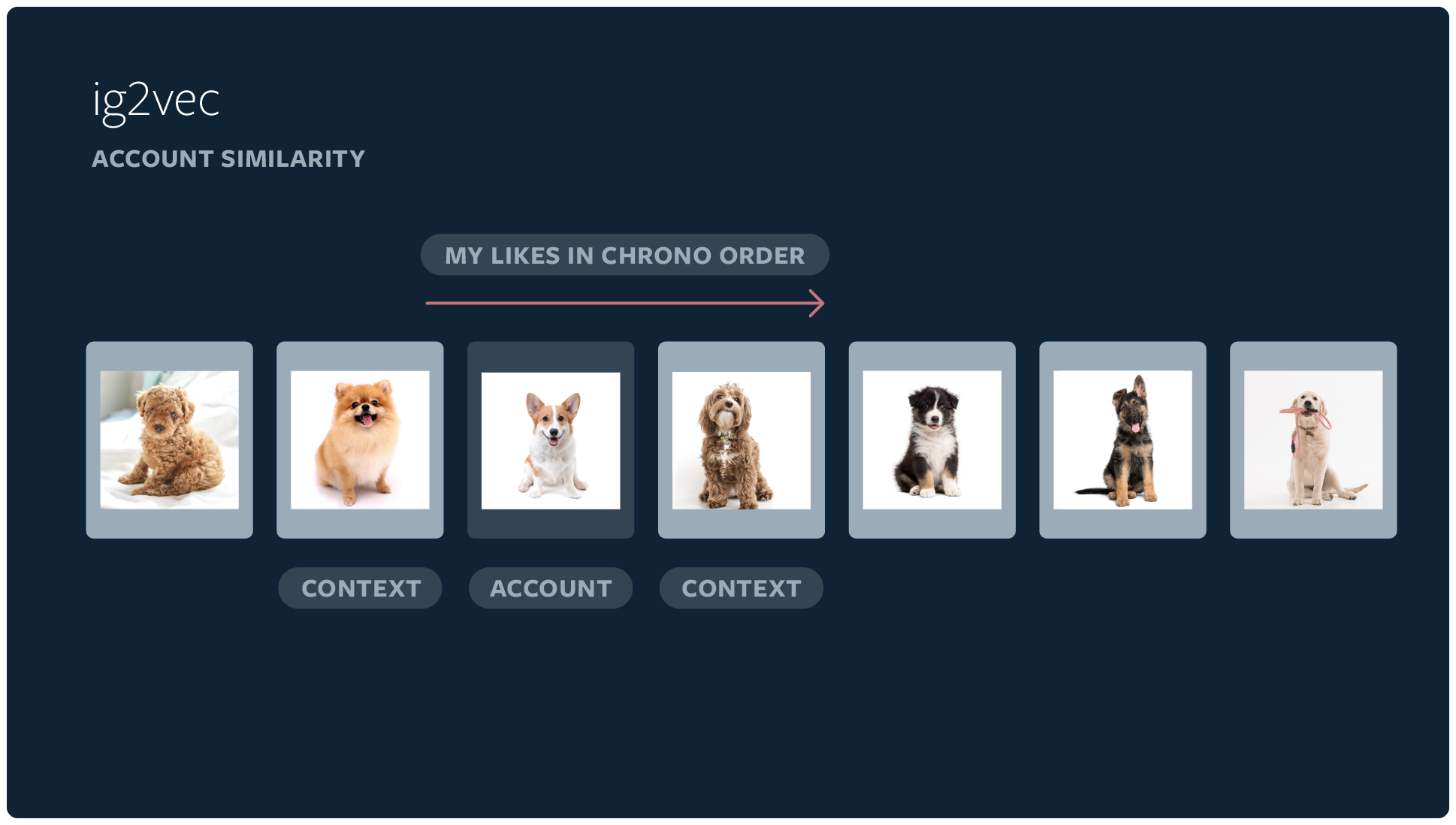
For instance, when you like several posts in a row, they’re more likely to be linked in some way even if Instagram’s algorithms can’t quite see it:
If an individual interacts with a sequence of accounts in the same session, it’s more likely to be topically coherent compared with a random sequence of accounts from the diverse range of Instagram accounts. This helps us identify topically similar accounts.
People just tend to look into stuff that way, going from one travel-focused account to the next, or focusing on animals because they need a pick-me up. All that information gets sucked up by the algorithm and inspected for relevance. Of course deliberate actions like “see fewer posts like this” and blocking accounts has a lot of weight as well.
From “seed accounts” to a top 25
The process of getting from a couple billion posts to just two dozen can be pretty difficult, but you can cut the problem down to manageable size by limiting the Explore tab to accounts linked in some way to accounts the user has already liked or saved posts from. These are called “seed accounts” because everything else in the process really grows out of them.
Because of how the machine learning system represents accounts and their topics inside itself, it’s super easy for it to find a couple hundred similar accounts.
Imagine if you know someone likes a particular reddish-orange marble and you need to find some more like it. If you just dip your hand into a sack of marbles you’re unlikely to find one quickly. Even if you pour them out on the floor you’ll still have to hunt around for a bit. But if you’ve already organized them by color, all you have to do is reach into the general vicinity of the marble they like and you’re almost guaranteed to pick a winner.
The machine learning model does that by giving all these accounts a sort of location in a virtual space, and the closer two are in that space, the closer they are topically.
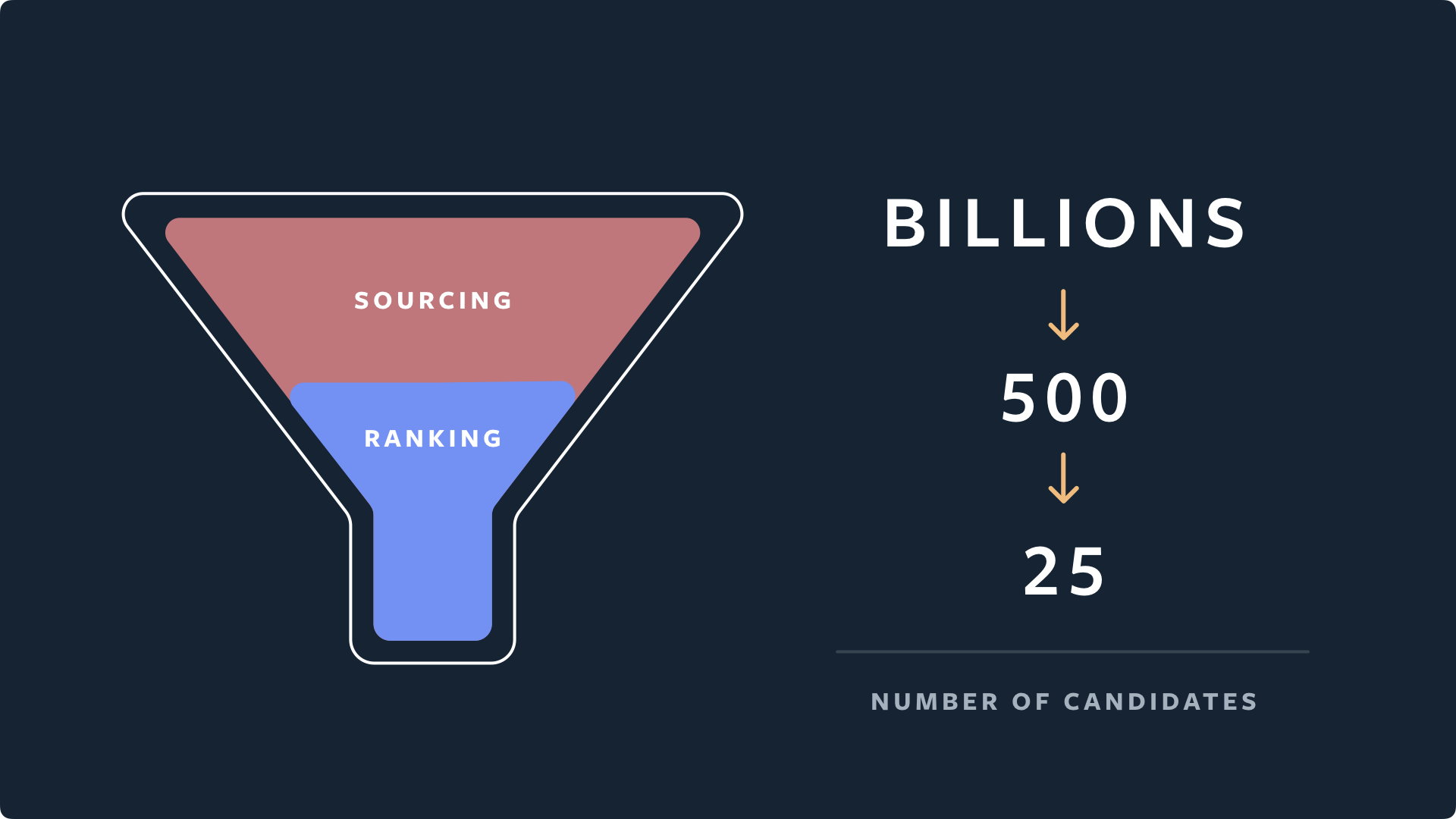
So the really hard part of paring down a set of billions to a set of hundreds is basically already accomplished by the way the accounts are classified.
From there Instagram does three passes with neural networks of increasing complexity.
First, slightly confusingly, is a simpler, combined version of the next two processes, which takes it from 500 to 150 accounts. This is a little weird, but think about it this way: This neural network has seen steps 2 and 3 happen many times and has a pretty good idea of what they do. Sort of like if you’d seen cookies get made enough times that you could guess at a recipe. You’d probably get close, but you also wouldn’t want to publish it to like a hundred million people. So this step just gets the obvious stuff right.
Second is a computationally cheap neural network that uses way more signals than the simple topical similarity mentioned above. Here’s where your individual likes come into play, as well as the deeper data about accounts. You like travel, sure, but in particular you like couples traveling — both things the marble-sorting algorithm above can help with. Other parameters, like a post’s general popularity, or actually its being different from the other posts in the mix, figure in as well. That skims another 100 off the top, leaving 50.
Third is a computationally expensive version of the above, which does another pass on those 50 and cuts them in half, basically by looking closer and taking the time to include, perhaps, a thousand data points each rather than a hundred.
I guess that was kind of long for a “takeaway.” Don’t worry, the next one is quick.
And of course, no 
“We want to make sure the content we recommend is both safe and appropriate for a global community of many ages on Explore,” they write. “Using a variety of signals, we filter out content we can identify as not being eligible to be recommended.”
So now you know why you don’t get any of that in Explore.






Online rummy cos sets up TRF to self-regulate the sector
RIPE, EU's regional internet registry, says it has run out of new IPv4 addresses and any returned will be allotted via waitlist, urges faster adoption of IPv6 (Kieren McCarthy/The Register)

Kieren McCarthy / The Register:
RIPE, EU's regional internet registry, says it has run out of new IPv4 addresses and any returned will be allotted via waitlist, urges faster adoption of IPv6 — So will you all please move to IPv6? World: Nope. — Analysis It happened four years ago. And again two years ago. And last year.
Taiwan’s Appier raises $80M for AI-based marketing technology
Artificial intelligence continues to be the theme of the moment in enterprise software, and today a company out of Asia that has built a suite of AI-powered marketing and ad tools is announcing a round of funding. Appier, a Taipei-based startup that provides an artificial intelligence engine to brands and retailers to help improve customer engagement, predict purchasing and improve conversions on their sites, has picked up $80 million.
This Series D includes TGVest Capital, HOPU-Arm Innovation Fund (SoftBank owns Arm), Temasek’s Pavilion Capital, Insignia Venture Partners, JAFCO Investment and UMC Capital. The company has raised $162 million to date, with previous investors including Alibaba, Sequoia, SoftBank, and Line. (The company is not disclosing its valuation but says it’s been growing since its Series C and it’s an upround. Appier now has around 1,000 customers.
Marketing technology — the bigger area of software that marketing and advertising people use to help launch, optimize and measure marketing campaigns — sometimes sits under the shadow of adtech, but in reality it’s estimated to be a $121 billion business, and growing as marketers for brands, retailers and others turn to data science to improve how they execute their work and to supplement what has traditionally been a business that operates on human precedents, psychology and hunches.
While the US and UK account for around half of all that spend, that leaves an interesting opening in markets like Asia Pacific: the customer base is still nascent but growing, and the number of startups that are focusing on the region are fewer, meaning less competition for business.
Those open waters became some of the impetus for founding Appier in Asia. Appier’s CEO, Chih-Han Yu, studied computer science and AI in graduate school at Sanford and then Harvard for his PhD, looking at how to use human gait data and machine learning to design better orthotics systems.
(If it seems like a big leap — no pun intended — to move from orthotics to sales conversions, it’s not an unusual path when you consider that for AI scientists, both are essentially mathematical problems, jumps that other AI startup founders have also made.) Ultimately, Yu decided to move back home to found his company with Winnie Lee (COO) and Joe Su (CTO).
In Asia things have been growing so fast that it seemed like an easy entry point to us,” Yu said. The company is already pan-Asian, headquartered in Taiwan, with offices in Japan and Singapore, and with a list of investors that span all those geographies and more.
Yu noted (in answer to my question about it) that while some of the investors in this round have ties to Hong Kong, there have been no tensions in respect of the current political situation unfolding between the Mainland and its special administrative region.
Appier’s initial and core product is a cross-platform advertising engine, CrossX, which covers retargeting and app installations, but also provides deep learning to help publishers and brands discover new audiences for their products.
This is still the company’s most popular product, but around it, Appier has built a series of other services around the basic concept of better customer information, specifically sourcing and utilising customer data in more intelligent (and, Yu says, anonimised) ways. This has included making acquisitions — of QGraph and Emotion Intelligence (Emin) to bring in more analytics and functionality into the platform.
Yu said that the funding will be used to expand further in the region, where it is currently live in 12 countries and works with a number of large local brands, and the Asian arm of global brands (those customers include the supermarket chain Carrefour, Audi and Estee Lauder), to improve their marketing work.
“Appier is riding a strong long-term trend for enterprises leveraging data to make smarter decisions,” said DC Cheng, Chairman of TGVest Capital, in a statement. “Thanks to its unique use of AI technology in the digital marketing space, Appier has been a category leader since its inception and has the opportunity to expand into new corporate functions where data-based decisions are made. We share Appier’s ambition and we are excited to be a partner to the company. We are confident that Appier will continue to grow as a sustainable technology company at the forefront of technology innovation.”


AWS Translate comes to 22 new languages and 6 new regions
AWS seems to be using this week to get some news out ahead of its annual re:Invent developer conference in Las Vegas next week. In addition to new IoT services and updates to its Rekognition AI service, the company also today announced that it is bringing 22 new languages to its AWS Translate service and that it is expanding support for the service to six new regions.
The new languages, which are now generally available, are Afrikaans, Albanian, Amharic, Azerbaijani, Bengali, Bosnian, Bulgarian, Croatian, Dari, Estonian, Canadian French, Georgian, Hausa, Latvian, Pashto, Serbian, Slovak, Slovenian, Somali, Swahili, Tagalog and Tamil. With these 22 new languages, the service now supports a total of 54 languages and 2,804 language pairs.
With this, the service is now available in 17 regions, which now include US West (N. California), Europe (London), Europe (Paris), Europe (Stockholm), Asia Pacific (Hong Kong) and Asia Pacific (Sydney). With this, more users will be able to translate text right where it’s stored, without having to move it to other regions first (which would, of course, also incur additional cost).
The free tier of AWS Translate includes 2 million characters for the twelve months.


How to add ISO images to VirtualBox 6
Palo Alto Networks to acquire Aporeto, which provides identity-based access control to secure workloads across all infrastructures, for $150M in cash (Stephanie Condon/ZDNet)

Stephanie Condon / ZDNet:
Palo Alto Networks to acquire Aporeto, which provides identity-based access control to secure workloads across all infrastructures, for $150M in cash — Meanwhile, Palo Alto reported Q1 results above expectations; Nutanix also reported solid Q1 results. — Palo Alto Networks …
Sunday, November 24, 2019
OPSC Civil Service Exam Admit Card 2019 – DV Call Letter Download
Frozen 2 Opens to $350 Million, Biggest Disney Animation Weekend in India
Realme X50 With 5G Support, Dual Hole-Punch Design to Launch Soon
Twitter Now Lets You Enable 2-Factor Authentication Without a Phone Number
Web Inventor Has an Ambitious Plan to Take Back the Net
T-Mobile says it suffered a data breach that affected over one million customers, exposing their names, billing addresses, phone numbers, and more (Devin Coldewey/TechCrunch)

Devin Coldewey / TechCrunch:
T-Mobile says it suffered a data breach that affected over one million customers, exposing their names, billing addresses, phone numbers, and more — T-Mobile has confirmed a data breach affecting more than a million of its customers, whose personal data (but no financial or password data) was exposed to a malicious actor.
Once hailed as an AI visionary, Satya Nadella faces pressure as a compute crunch forces Microsoft to prioritize its own AI products over Azure cloud customers (Ashley Stewart/Business Insider)
Ashley Stewart / Business Insider : Once hailed as an AI visionary, Satya Nadella faces pressure as a compute crunch forces Microsoft to ...

-
Sohee Kim / Bloomberg : South Korean authorities are investigating a data leak at e-commerce giant Coupang that exposed ~33.7M accounts; ...
-
Top fintech companies are rushing to tap into this new consumer trend, with several of them offering digital solutions to small merchants. h...
